Abstract
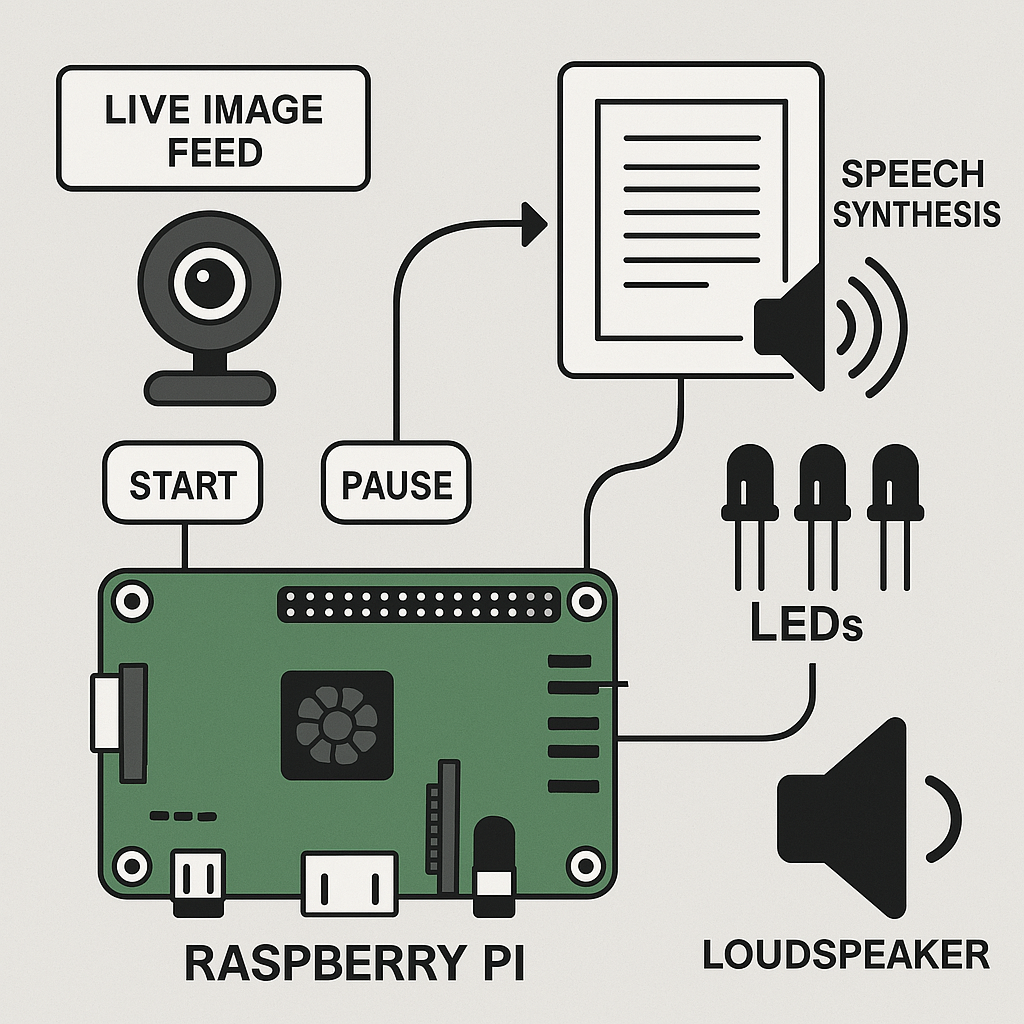
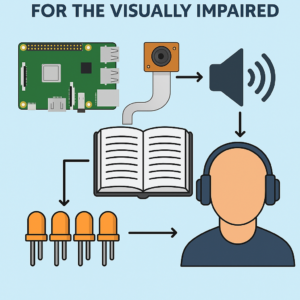
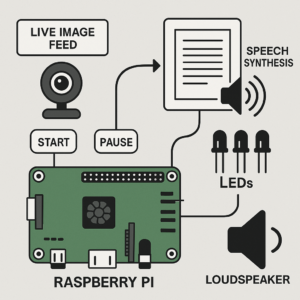
This project presents a real-time optical character recognition (OCR) and text-to-speech (TTS) system powered by a Raspberry Pi. It is designed to assist visually impaired individuals by converting printed or handwritten text captured via a camera into audible speech. The system uses OpenCV for image capture and preprocessing, pytesseract for multilingual OCR (English and Arabic), and Google’s Text-to-Speech engine for audio output. GPIO-controlled buttons initiate image capture and audio playback, while LEDs offer visual feedback. The integration of computer vision and speech synthesis on a compact, low-power platform demonstrates a practical solution for accessible reading aids.
Reviews
There are no reviews yet.